The reference is used to connect the parameter to a certain node/value in the model. To update that value when the parameter is changed. You'd use it when you have a single point in the model that uses the parameter, for example the processing time of one processor.
You don't have to enter anything into the reference field if you don't want to link the parameter to any one node. Binding the min/max/stream parameters to anything wouldn't really make sense in this case, for instance. Since they are only used to influence the distribution. The experimenter can change them regardless of a reference being set.
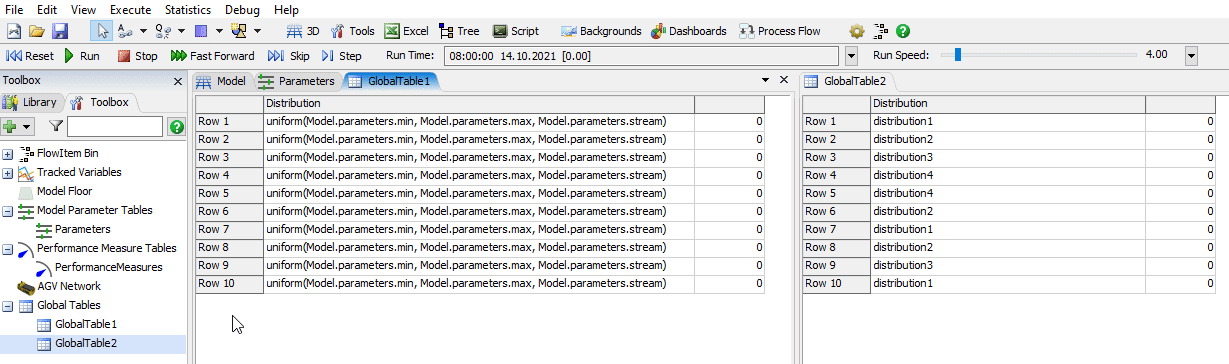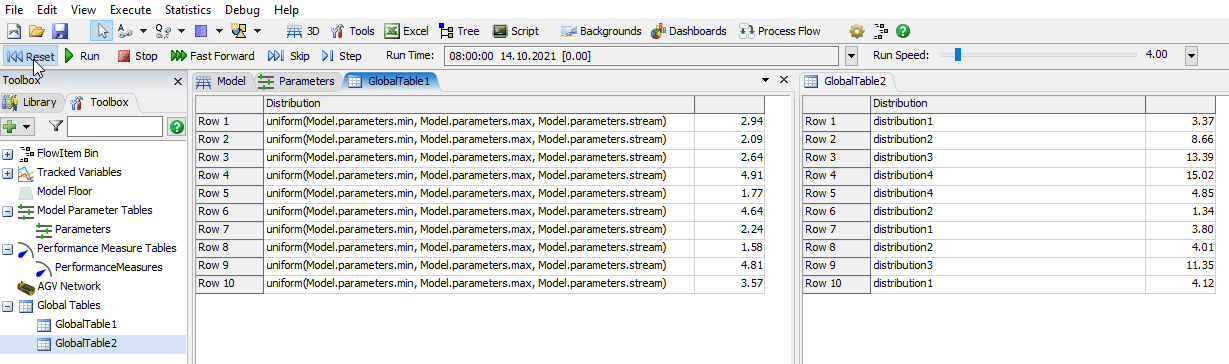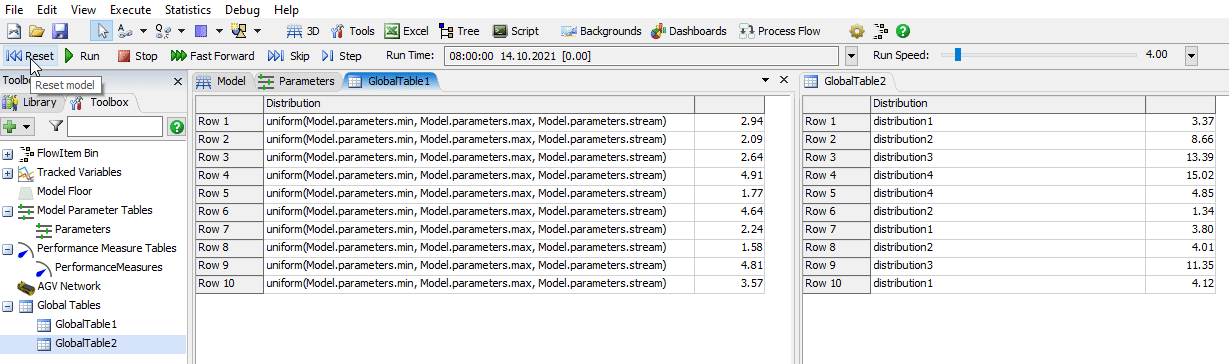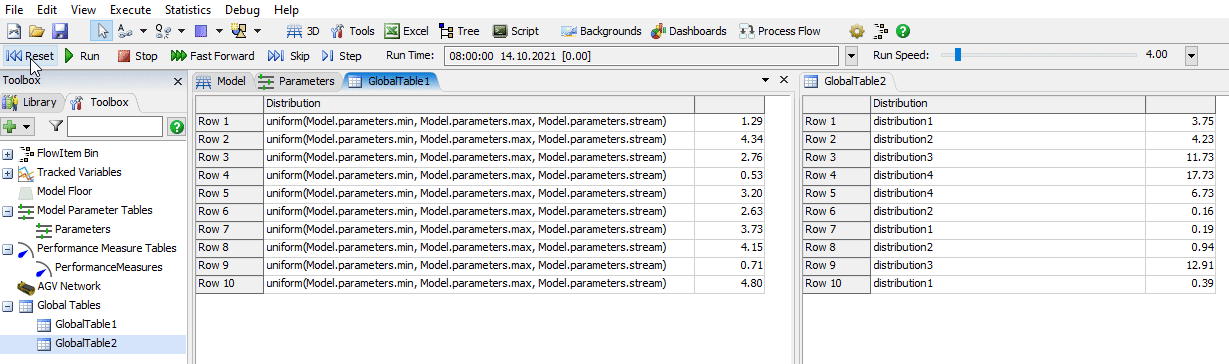
The "stream" could be seen as the seed of the random distribution. A different stream will lead to different results. By default, it is mostly filled in with the "getstream()" command that generates a unique stream number based on the object it is used in. This leads to better repeatability, as the numbers that are generated for any object/activity are independent of how often the distribution is used elsewhere. If you use the same stream everywhere, then adding an additional processor, for example, will have an impact on the processing times that are generated for the others during the run (it will take up some numbers that would have otherwise been used in the other objects). As such, model runs might be less comparable to each other when changes like that occur between them.
See also this post and links in the answer for more info on the stream.
https://answers.flexsim.com/questions/47022/what-representation-has-the-use-of-a-stream-in-the.html
I don't see any way to meaningfully vary the stream when using a parameter as a distribution like this. However, if the model run time is long enough, the variance caused by using the same stream shouldn't have a measurable impact on the results in most cases.
The code in the script window at the bottom is the other way to use a parameter in a model. Instead of connecting a single value to the parameter you can use it in multiple places to get the value of the parameter, in this case a random number according to the distribution. For example, you want to control the processing times of multiple processors with the parameter. Then you'd write "Model.parameters.distribution" in the field for the processing time of each one.
I used the script window to confirm that using other parameters in the distribution actually works as expected. When you click on the green arrow it will generate and display a new random value according to the distribution each time.







{kind=link}
{kind=link}
{kind=link}
{kind=link}